使用jekyll搭建站点,用markdown编写POST,如果图片都存在本地,而且repo存在类似github等国外网站的时候,速度就会非常慢。这个时候,如果图片放在图床或者对象存储器上,就比较轻量化了。我有一个腾讯云账号,对象存储服务每个月有10G的免费流量。之前都是使用自己写的上传脚本上传图片,然后将回传的地址复制到markdown文件中。
如果直接在vscode粘贴图片的过程就实现了上传,那就比较好了。搜索了一下,发现tencent-cloud-cos-upload-image这个插件可以实现该功能。不过使用的过程中,发现了在windows平台使用过程中的一个小bug。默认在windows中,path.seq为\符号,但是这个符号在cos中会被转移成文件名的一部分,导致无法正常上传到目标文件夹中。这个时候只能修改插件的代码了。
- 首先,如下图所示复制插件的id
- 根据id检索到插件所在的位置
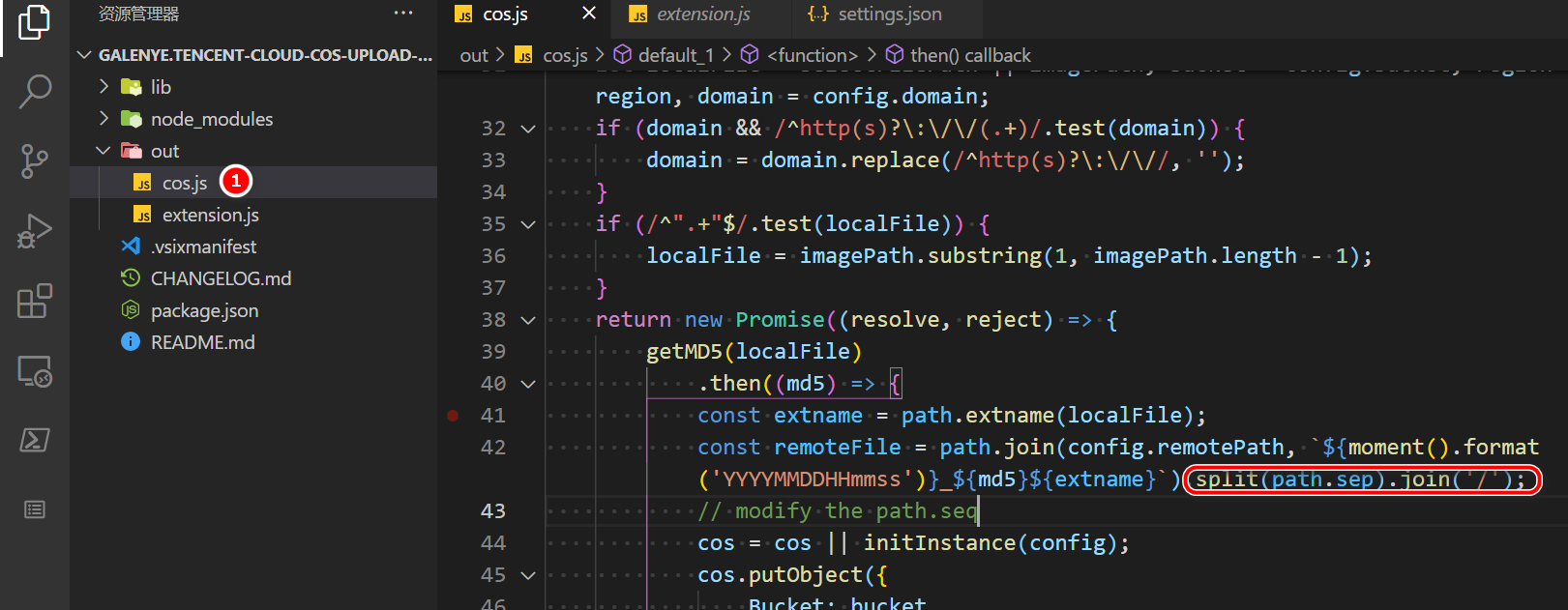
如上图所示,打开cos.js文件夹,增加红色方框处的代码,将path.seq从\更改成/,这样cos存储服务器可以正确识别路径,可以正确将图片文件上传到目标路径下了。